[k8s] 11. 쿠버네티스의 오토스케일링 (HPA, VPA, Cluster Autoscaler)

🌟 들어가며
대부분의 시스템은 요청이 많아질 때 자동으로 더 많은 리소스를 쓰고, 요청이 적을 땐 자동으로 리소스를 줄이기를 원한다. 예전에는 이런 처리를 직접 스크립트로 짜거나 배치로 조절했지만, Kubernetes는 이걸 기본 기능으로 제공한다. 그게 바로 오토스케일링(Autoscaling)이다.
Kubernetes에는 총 3가지 대표적인 오토스케일링 기능이 있다.
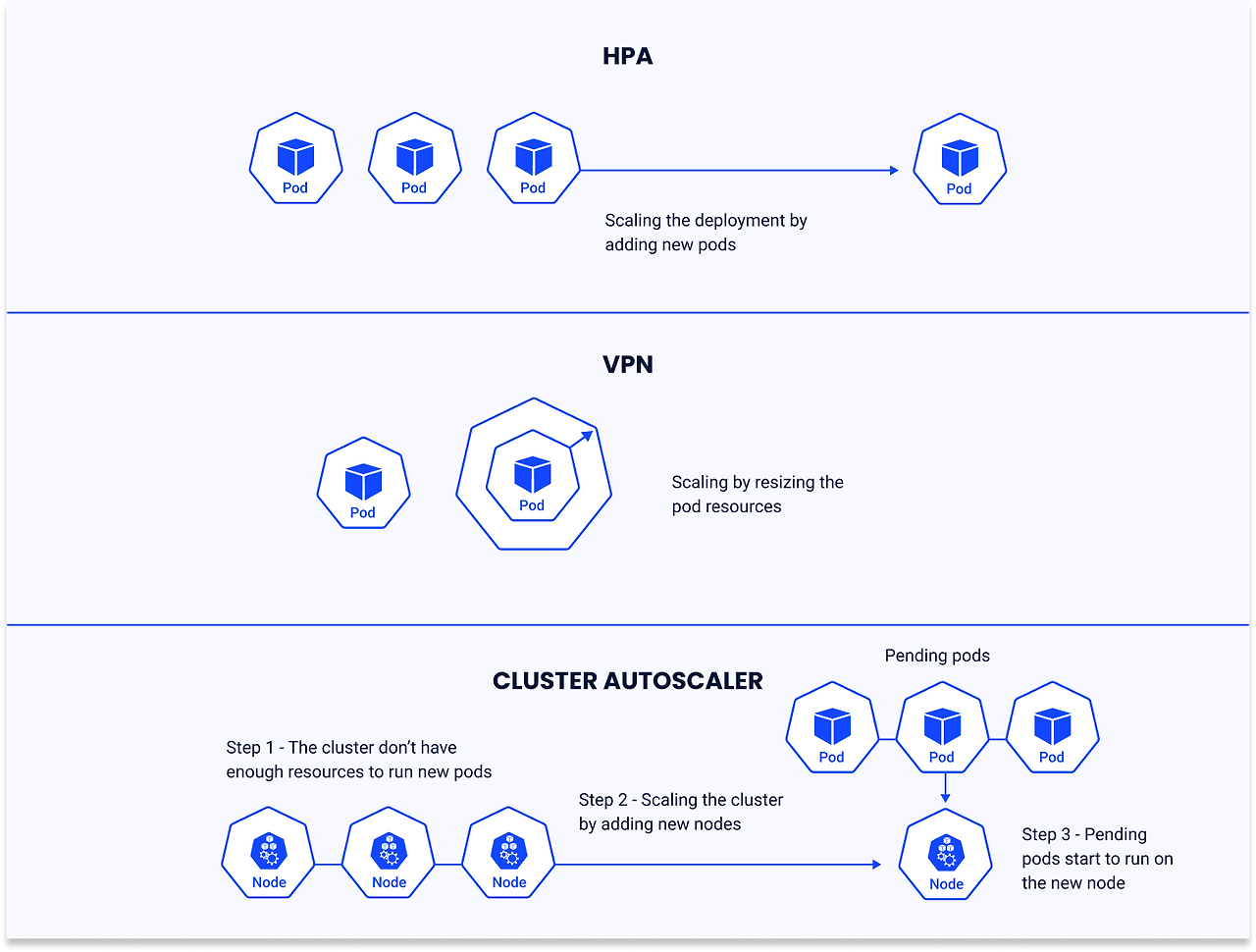
- HPA (Horizontal Pod Autoscaler) – Pod 수를 자동 조절
- VPA (Vertical Pod Autoscaler) – Pod에 할당된 자원(cpu/mem)을 조절
- Cluster Autoscaler – 노드 수를 자동 확장/축소
📈 HPA - 수평 확장 : Pod 개수 자동 조절
HPA는 CPU, 메모리, 또는 커스텀 메트릭 기반으로 Pod의 replica 개수를 자동으로 조정해주는 리소스이다.
기본적으로 CPU 사용률을 기준으로 많이 쓰면 늘리고, 덜 쓰면 줄이는 방식이다.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: my-app-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 2
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 60이 설정은 my-app Deployment를 대상으로, CPU 평균 사용률이 60%를 넘으면 Pod 수를 자동으로 2~10개 사이로 조절한다.
🔄 HPA 작동 흐름
metrics-server
│
▼
HPA Controller (Control Plane)
│
▼
Deployment/ReplicaSet/StatefulSet
│
▼
Pods (스케일 업/다운)HPA의 작동흐름은 아래와 같다.
- Kubernetes Metrics Server가 Pod의 리소스 사용량 수집
- HPA Controller가 평균 CPU 사용률 계산
- targetUtilization과 비교해서 replica 수 계산
- kubectl get hpa 명령어로 상태 확인 가능
HPA가 작동하기 위해서는 반드시 Metrics Server가 설치되어 있어야 작동한다.
AWS EKS의 경우 EKS Cluster를 생성하면 자동으로 metrics server가 설치된다.
여담이지만, 프로젝트 할때 EKS Cluster 생성에 처음 성공했을 때 팀원들에게 이 서버(metrics server) 누가 설치하셨어요? 했었더랬다..
자세한 내용은 아래 공식문서를 읽어보는게 좋다.
Horizontal Pod Autoscaling - Kubernetes 공식 문서
📊 VPA - 수직 확장 : 리소스 요청량 자동 조절
VPA는 Pod의 CPU/Memory 사용량을 관찰한 뒤, requests 값을 자동으로 추천하거나 수정해준다.
Pod를 재시작하면서 리소스를 조정하기 때문에, 실시간으로 줄이진 못하고 새로 뜰 때 적용된다.
HPA가 Pod의 수평 확장을 담당한다면, VPA는 수직 확장을 통해 개별 Pod의 리소스 할당량을 최적화한다.
💡 추천(Recommendation) 시스템
추천한다는 개념이 생소한데, VPA의 핵심 개념이다.
추천은 VPA가 Pod의 과거 및 현재 리소스 사용량을 분석해 최적의 리소스 요청 값을 제안하는 과정을 의미한다.
추천 시스템은 세 단계로 작동한다.
1️⃣ 메트릭 수집
Metrics Server를 통해 Pod의 CPU/메모리 사용량 데이터를 수집한다.
예시: Pod가 500m CPU를 사용하지만 2000m을 요청 중인 경우, 사용 패턴 분석을 시작한다.
2️⃣ 추천 값 계산
VPA Recommender는 다음을 고려해 최적값을 산출한다.
- 과거 사용량 추이(평균/피크 사용량)
- 메모리 부족(OOM) 이벤트
- QoS(Quality of Service) 클래스(Guaranteed, Burstable 등)
- 사용자 정의 리소스 정책
계산 결과 예시:
- Lower Bound: 800m CPU (최소 필요량)
- Target: 1000m CPU (권장값)
- Upper Bound: 1200m CPU (최대 한계)
3️⃣ 추천 적용
- Auto 모드: VPA Updater가 자동으로 Pod를 제거(evict)하고 새 리소스 요청으로 재생성
- Recreate 모드: Pod 재시작 시에만 적용
- Off 모드: 추천만 제공하고 자동 적용은 안 함
apiVersion: autoscaling.k8s.io/v1
kind: VerticalPodAutoscaler
metadata:
name: my-app-vpa
spec:
targetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
updatePolicy:
updateMode: "Auto"Auto 모드는 Pod를 재시작시켜 리소스 조정까지 해준다.
updateMode: "Off"로 두면 추천만 하고 자동 적용은 안 한다.
⚠️ HPA + VPA는 안된다?
주의할 점이 있는데, 대부분 HPA와 VPA는 같이 쓸 수 없다.
HPA는 Pod 수를 조정하고, VPA는 Pod당 자원을 조정한다.
그런데 HPA는 CPU 요청량 기준으로 Pod을 확장하므로, VPA가 requests를 변경하면 HPA의 판단 기준이 계속 바뀌게 된다. → 충돌 위험
때문에 HPA는 CPU 기준, VPA는 memory만 쓰고 조합해서 쓰는 경우도 있다.
🖥️ Cluster Autoscaler(CA) - 노드 수 자동 조정
Pod가 너무 많아지면 더 이상 스케줄될 노드(Worker Node)가 없을 수 있다.
이 때, 노드를 자동으로 늘려주는 역할을 하는 게 Cluster Autoscaler이다.
반대로, 리소스가 남아도는 노드는 제거해서 비용도 줄일 수 있다.
🔄 CA 동작 원리
CA는 아래의 동작 원리로 작동한다.
1️⃣ 스케줄 불가(Pending) 파드 감지
CA는 주기적으로(기본 10초 등) 클러스터 상태를 점검하여, 현재 노드 자원 부족으로 스케줄되지 못하고 대기 중인 파드가 있는지 확인한다.
2️⃣ 노드 확장(Scale Up)
만약 파드가 자원 부족으로 스케줄되지 못하고 있다면, CA는 노드 그룹(예: AWS ASG, GCP MIG 등)에 새 노드를 추가한다.
노드가 클러스터에 등록되면, 스케줄러가 대기 중이던 파드를 새 노드에 할당한다.
3️⃣ 노드 축소(Scale Down)
반대로, 일부 노드의 자원 사용률이 지속적으로 낮고, 해당 노드의 파드가 다른 노드로 옮겨질 수 있다면, CA는 해당 노드를 축소(종료)하여 리소스 낭비를 방지한다.
여러 노드 그룹이 있을 경우, 확장 시 다음과 같은 전략을 지원한다.
- Random(무작위)
- Most Pods(가장 많은 파드를 수용할 수 있는 그룹)
- Least-waste(가장 적은 자원 낭비)
- Price(가장 저렴한 비용)
- Priority(우선순위 높은 그룹)
4️⃣ 노드풀 최소/최대 크기 지정
각 노드풀마다 최소/최대 노드 수를 지정할 수 있으며, 이 범위 내에서만 자동 확장/축소가 일어난다.
5️⃣ 리소스 요청 기반 판단
CA는 파드의 실제 사용량이 아니라, 파드의 resource requests(필수 리소스 요청값)를 기준으로 동작한다.
따라서 파드에 적절한 requests/limits 설정이 필수이다.
🛠️ AWS EKS 설정 예시
참고로, AWS EKS의 경우 클러스터 생성 시 설정해주거나 Helm Chart로 설치한다.
eksctl create nodegroup \
--cluster my-cluster \
--name spot-group \
--spot \
--min-size 1 \
--max-size 5EKS 기준, NodeGroup 설정 예시다.
노드 그룹에 min/max 설정을 해두면 Cluster Autoscaler가 그 범위 내에서 조절해준다.
🎯 마치며
위 3가지 개념을 표로 정리하면 아래와 같다.
| 기능 | 대상 | 확장 기준 | 제한 사항 |
|---|---|---|---|
| HPA | Pod replica | CPU, Memory, Custom Metrics | metrics-server 필요 |
| VPA | Pod resource | 과거 사용량 분석 | 재시작 필요, HPA와 충돌 |
| Cluster Autoscaler | Node 수 | Pending Pod, idle 노드 | 클라우드 연동 필요 |
보통은, HPA + Cluster Autoscaler 조합이 가장 많이 사용된다고 한다.
Pod가 늘어나면 자동으로 노드도 추가되어 수용할 수 있게 되기 때문이다.
VPA는 보통 추천 모드로 활용해서 requests 설정을 튜닝하는 용도로 유용하다고 한다.